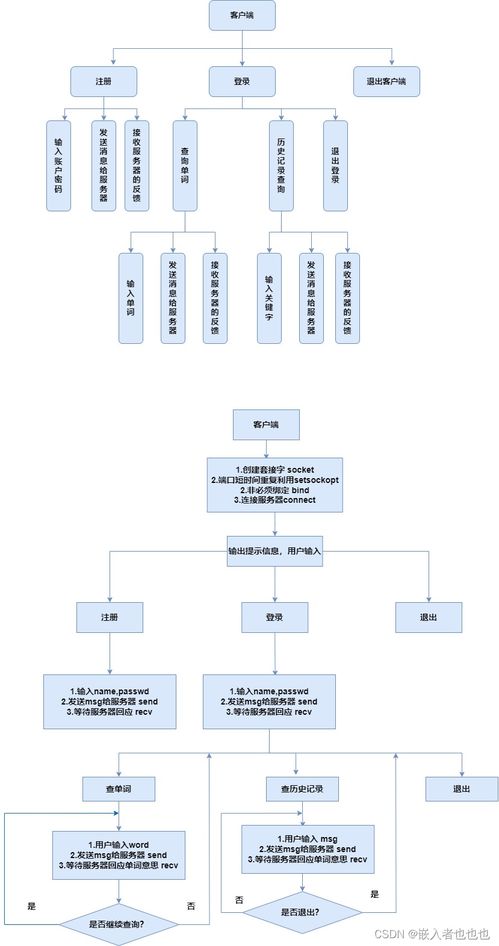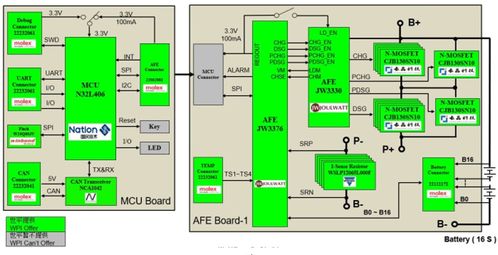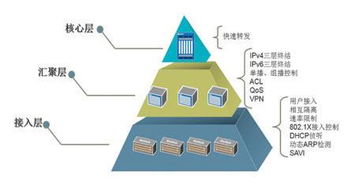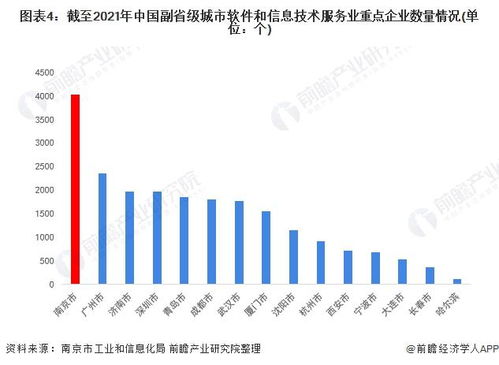
在当今数据驱动的时代,知识图谱作为一种结构化的知识表示方法,正逐渐成为企业智能决策和信息系统集成的核心工具。自下而上的构建方法,强调从原始数据出发,逐步抽象和整合,最终形成高层次的知识网络。本文将详细解析在信息系统集成服务中,自下而上构建知识图谱的全过程。
一、需求分析与目标定义
构建知识图谱的第一步是明确业务需求与目标。在信息系统集成服务中,这通常涉及跨系统、跨平台的数据整合与知识发现。例如,企业可能希望整合客户关系管理(CRM)、企业资源规划(ERP)和供应链管理(SCM)系统中的数据,以构建一个统一的客户知识图谱,支持精准营销或风险预测。此阶段需与业务部门紧密合作,确定知识图谱的覆盖范围、核心实体(如客户、产品、订单)和关键关系。
二、数据采集与预处理
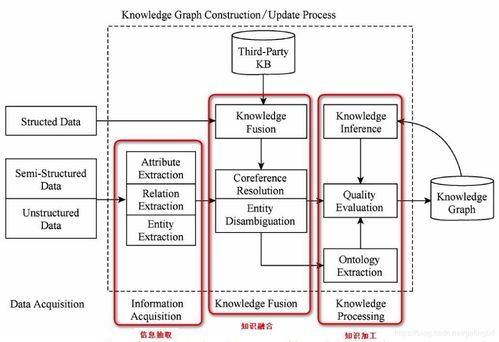
自下而上方法的基础是原始数据。数据源可能包括结构化数据库(如SQL)、半结构化数据(如XML、JSON)和非结构化文本(如报告、邮件)。在信息系统集成中,常通过ETL(抽取、转换、加载)工具或API接口从多个异构系统中采集数据。预处理环节至关重要,包括数据清洗(去除重复、错误值)、标准化(统一格式)和归一化(如日期转换),以确保数据质量。例如,不同系统中的客户名称可能需统一为规范格式。
三、实体识别与关系抽取
这是知识图谱构建的核心步骤。实体识别旨在从数据中识别出关键对象,如人名、组织、产品等;关系抽取则确定实体间的关联,如“客户A购买产品B”。在信息系统集成场景中,可利用自然语言处理(NLP)技术处理非结构化文本,或基于规则和机器学习模型从结构化数据中提取信息。例如,从订单日志中识别“订单”实体和“包含”关系。此阶段需定义本体(Ontology),即实体和关系的分类体系,以指导后续整合。
四、知识融合与存储
来自不同系统的数据往往存在冗余或冲突,知识融合旨在解决这些问题。通过实体对齐(Entity Alignment)技术,将指代同一实体的不同表述(如“IBM”和“International Business Machines”)合并;通过数据消歧,消除语义歧义。融合后的知识需存储到图数据库中,如Neo4j或JanusGraph,这些数据库专为处理图结构数据设计,支持高效的关系查询。在信息系统集成中,这步确保了知识图谱的一致性和可扩展性。
五、图谱构建与可视化
基于存储的数据,构建完整的知识图谱模型。这包括定义节点(实体)和边(关系),并添加属性(如客户的年龄、产品的价格)。可视化工具(如Gephi)可帮助直观展示图谱结构,便于业务人员理解和验证。例如,在集成服务中,可构建一个展示客户、订单和产品交互关系的网络图,以揭示潜在的业务模式。
六、应用集成与优化
构建好的知识图谱需与现有信息系统集成,以提供智能服务。这通常通过API接口或中间件实现,例如将知识图谱嵌入到CRM系统中,支持智能推荐或欺诈检测。持续优化是必要环节,包括根据用户反馈更新图谱、监控性能以及扩展新数据源。在信息系统集成服务中,还需确保知识图谱与业务流程的协同,如自动化报告生成或实时决策支持。
七、挑战与未来展望
自下而上构建知识图谱在信息系统集成中面临诸多挑战:数据异构性、实时性要求高、以及隐私安全风险。随着人工智能和云计算的发展,自动化构建工具和联邦学习技术有望简化这一过程,使知识图谱更广泛地服务于企业数字化转型。
自下而上构建知识图谱是一个从数据到知识的渐进过程,在信息系统集成服务中,它不仅能提升数据价值,还能驱动智能业务创新。通过系统性实施上述步骤,企业可构建出动态、可扩展的知识基础,为复杂决策提供强大支撑。